Kubernetes Pod驱逐和迁移
网上查了一下,出现这种情况不在少数。用户的应用我们没办法控制,好在K8S本身提供了完善的Pod迁移和驱逐机制,能够在异常情况下保证集群和大多数应用正常运行,下面来详细看一下。
下面是一个比较完整的配置示例:
spec:
- containers:
- – name:qos-demo-ctr
- image:nginx
- resources:
- limits:
- memory:”200Mi”
- cpu:”700m”
- requests:
- memory:”200Mi”
- cpu:”700m”
可以配置的资源类型包括:
• cpu
• memory
• storage
• ephemeral-storage
我们本次要讲的驱逐和迁移逻辑主要与cpu和memory相关,与另外两个关系不大。
那么如果你是用户的话,关于这个字段的配置,有两条建议:
1. 不要偷懒,limits和requests都填好。
2. 不要贪心,吃多少拿多少。
不要误会,这不是吃自助餐,配多了也没有用不完会收费的问题,这两条建议完全是从资源紧缺的场景下应用存活的角度考虑。
Kubernetes会使用Linux的OOM killer能力,OOM killer是linux系统中控制内存不足时内核行为的插件。简单说明下Kubernetes用到的OOM killer的工作逻辑:
1. 每个应用有一个分值,即OOMScoreAdj得分越高,越先被杀掉。(小时候老师不是这么说的呀)
2. 当分值一样时,申请资源越多越先被杀掉。(杀个最胖的,少拉仇恨)
下面看一下OOMScoreAdj的计算方式。
在Kubernetes里,关于OOM分值的计算,会将Pod分为三类,分别是Guaranteed/Burstable/BestEffort。分类依据如下表所示:
| 条件 | 分类 | 分值 |
| pod中每一个容器都有cpu和memory的limit和request | Guaranteed | -998 |
| pod中所有容器没有任何资源限制 | BestEffort | 1000 |
| 其他 | Burstable | 2~999 |
其中Burstable的Pod分值计算公式如下:
1000 – (1000*memoryRequest)/memoryCapacity
另外程序里加上了两个限制,保证这个分值的范围在2~999之间。
我们知道OOM的分值越高越容易被杀掉,所以如果没有配置任何资源限制的话,分值就是1000,肯定最先被杀掉,假设pod1的容器只在资源限制里随便配了一个字段,而pod2什么都没配,那么肯定pod2会比pod1先被杀掉,因为程序保证了pod1最大分值为999,会比pod2低一分。
当然最好还是都配置好,这样OOM的分值就会是-998,这是一个特别高的保证优先级,基本上如果这个优先级的Pod被杀掉,那就表示这个节点马上要挂掉了。
除了用户自己的Pod之外,系统进程也都会有一个自己的分值。具体如下表所示:
| 组件 | 分值 |
| kubelet | -999 |
| kube-proxy | -999 |
| docker | -999 |
| pod-infra-container | -998 |
注:详细信息可以查看源码
kubeGenericRuntimeManager.generateLinuxContainerConfig()
根据上面的描述,当节点资源紧缺的时候,一些Pod会被系统清掉。这个能够保证集群能在最大程度上正常运行。但是这需要一个前提,就是调度器能够根据资源使用情况调度Pod。否则就可能出现类似手机上一核工作七核围观的情况。或者一个Pod刚被清掉,又被调度器调度到这个节点上,一个Pod杀来杀去,还是有点残忍的。
好在Scheduler有根据Node资源的调度策略,可以平衡各个节点的资源。调度时Scheduler会根据节点的资源使用情况进行排序,并计算得到一个分值,算入最后节点的总得分中。这种策略当然不会保证pod必然调度到资源使用最少的节点中(实际也没有那种必要),但肯定会把节点资源使用情况作为一个考量因素。
相关策略及分值计算如下表所示:
| 策略 | 说明 |
| LeastResourceAllocation | 计算pod调度到节点之后,节点剩余cpu和内存占总cpu和内存的比例,比例越高优先级越高 |
| BalancedResourceAllocation | 计算节点上cpu/内存/存储使用比例三者的方差,方差越小越优先 |
| MostResourceAllocation | 计算pod调度到节点之后,节点所用cpu和内存占总cpu和内存的比例,比例越高优先级越高。(自动扩所容用到) |
上面是计算方式的简单描述,我们需要注意到的点有:
•BalancedResourceAllocation策略目的是让节点资源使用更均衡,防止某一种资源占满了,另外两种资源还完全没用的情况,这样的话资源利用率也不高。但是它必须与LeastResourceAllocation结合使用。
•三种资源相关的策略都会假设待调度的pod已经调度到节点上来计算节点已用资源。计算资源的时候只用到pod各个容器的resource.request,不考虑limit。如果没有配置request则使用默认值,cpu 0.1核,内存200M。
•LeastResourceAllocation中以资源使用量占节点可用资源的比值为准,而非资源的绝对量。
注:更多关于调度策略的细节,可以查看源码:
pkg\scheduler\algorithm\priorities\most_requested.go
pkg\scheduler\algorithm\priorities\resource_allocation.go
pkg\scheduler\algorithm\priorities\balanced_resource_allocation.go
pkg\scheduler\algorithm\priorities\least_requested.go
调度策略能保证在布置pod的时候不给节点太大压力,但是如果已经调度到节点上的Pod不好好跑,占了太多资源怎么办呢?
虽然有前面介绍的OOM killer,但是这相当于我们的最后一条防线,但是玩过植物大战僵尸的人都知道,肯定不能靠后面的小车档僵尸,毕竟等到了这一步的时候,节点已经在崩溃的边缘了。
所以有了Kubelet驱逐机制,当节点资源较少时,Kubelet为了保证节点稳定运行,会驱逐一些Pod。
资源类型
kubelet支持通过下面几种资源类型触发驱逐,包括:
| 驱逐信号 | 描述 |
| memory.available | memory.available := node.status.capacity[memory] – node.stats.memory.workingSet |
| nodefs.available | nodefs.available := node.stats.fs.available |
| nodefs.inodesFree | nodefs.inodesFree := node.stats.fs.inodesFree |
| imagefs.available | imagefs.available := node.stats.runtime.imagefs.available |
| imagefs.inodesFree | imagefs.inodesFree := node.stats.runtime.imagefs.inodesFree |
可以根据上面5中资源类型配置驱逐触发条件,触发条件的形式如下:
<eviction-signal><operator><quantity>
eviction-signal即上表列出的驱逐信号,operator是判断方法,目前只支持<,quantity可以是资源的数值和百分比,比如,配置memory的驱逐策略,可以是memory.available<10%,也可以是memory.available<1Gi。
两种驱逐形式
Kubelet有软驱逐和硬驱逐两种形式,主要区别如下:
•硬驱逐:可用资源小于规定的数值或百分比时立即出发驱逐。
•软驱逐:可用资源小于规定数值或百分比并持续一定时间后触发驱逐,并且被驱逐的Pod有优雅删除时间。
可以通过Kubelet的flag配置软驱逐或硬驱逐,以及相关参数,示例如下:
第一种情况
# 当可用存储<100Mi,或可用nodefs<100Mi触发驱逐
–eviction-hard=memory.available<100Mi[,][nodefs.available<100Mi]
另一种情况
# 当可用存储<100Mi,持续时间超过1分钟后触发驱逐,被驱逐pod的优雅删除时间为30s.
–eviction-hard=memory.available<100Mi –eviction-soft-grace-period=1m –eviction-max-pod-grace-period=30s
系统资源分配
前文描述的逻辑,无论是OOM killer,还是根据资源的调度,或者是Kubelet的驱逐,默认情况下都认为Pod能够使用节点全部可用容量。这肯定有其它问题,因为节点内还有很多系统和Kubernetes进程,这些进程使用的系统资源应该预留出来。
Kubelet的Node Allocatable特性就是为了这一目的。在Node Allocatable的规划中,Node资源可以分成四份,这样实际pod可能使用的资源就可以如下图所示.
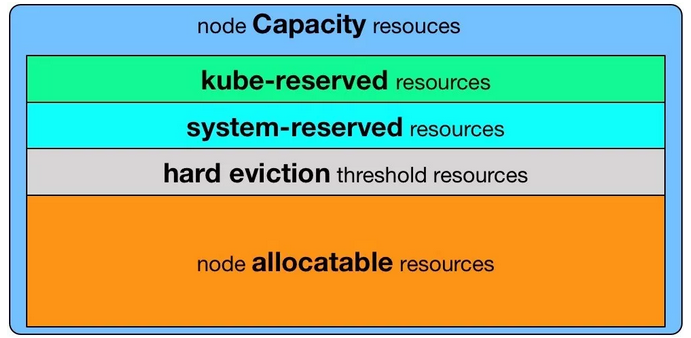
•Kube Reserved:为Kubelet/node problm detector等系统守护进程预留的资源。
•System Reserved:为sshd/udev等系统守护进程预留的资源.
•Eviction Thresholds:驱逐触发条件,当pod使用资源数量到达这一条线时触发驱逐。这样从驱逐到触发OOM killer会有一个缓冲。
具体使用过程中,需要通过配置Kubelet的flag允许系统资源分配,举个例子,为kube和system进场预留,具体配置如下所示:
# 为kube和system进程预留cpu,内存,硬盘资源.
# 为kube和system创建对应的cgroup
# node资源分配分为pods,kube-reserved,system-reserved三种
# 当可用内存<500Mi时触发驱逐
–enforce-node-allocatable=pods,kube-reserved,system-reserved
–kube-reserved-cgroup=/kubelet.service
–system-reserved-cgroup=/system.slice
–kube-reserved=cpu=1,memory=2Gi,ephemeral-storage=1Gi
–system-reserved=cpu=500m,memory=1Gi,ephemeral-storage=1Gi
–eviction-hard=memory.available<500Mi,nodefs.available<10%
其他相关配置
•–eviction-minimum-reclaim=memory.available=100Mi:最小资源回收量,防止每次驱逐只回收一点点资源,造成资源波动的情况。
•–eviction-pressure-transition-period=5m:node异常状态恢复时间,防止资源波动的时候node状态频繁切换。
注:具体逻辑可查看代码
// 执行驱逐
pkg\kubelet\eviction\eviction_manager.go(managerImpl.synchronize)
// 根据参数创建驱逐触发条件
pkg\kubelet\eviction\helpers.go(ParseThresholdConfig)
// 获取节点状态
pkg\kubelet\server\stats\summary.go(summaryProviderImpl.Get)
// 配置node资源分配cgroup
pkg\kubelet\cm\node_container_manager.go(containerManagerImpl.enforceNodeAllocatableCgroups)
以上工作理论上可以保证在整个系统负载不高的情况下,单个Node不会因为资源不足而挂掉。
但是实际应用中,Node难免会因为这样那样的原因处于异常状态,这时候就需要node-controller的Pod迁移机制,把异常Node上的Pod迁移到其他地方。
当Node Ready状态处于unknown或false ,且持续时间超过–pod-eviction-timeout规定时间后使用驱逐或者taint-toleration的形式将Node上的Pod迁移到其他节点。
实际执行过程中会将有问题的节点添加到迁移队列,并且按照一定算法严格控制节点上Pod的迁移速率。在执行Pod迁移时,会进行如下判定:
1.大集群判定:根据large-cluster-size-threshold参数判定,当集群Node数量大于这一数值是判定为大集群,默认是50.
2.集群被严重破坏判定:当集群内异常node数量大于2,且比例大于unhealthy-zone-threshold规定比例时,认为集群被严重破坏,默认这一数值是0.55。
根据上面两个判定,将集群分为三种状态,针对这三种状态执行不同的迁移速率:
•正常状态,按照node-eviction-rate规定的速率迁移,默认是0.1qps,即每10s取出一个异常节点,迁移上面的pod。
•大集群,单个zone被严重破坏场景,执行secondary-node-eviction-rate规定的第二迁移速率,默认为0.01,即100s执行一次迁移。
•大集群,所有zone被严重破坏场景,正常迁移.
•小集群严重破坏场景,不执行迁移。
另外,在1.9及以后版本可以打开Feature-gate TaintBasedEvictions后可以使用基于taint的迁移,逻辑与正常的迁移机制相同,不过可以通过在Pod中配置toleration控制Pod迁移时间,或者控制节点异常状态时Pod不被迁移。

