前后端对Long型的理解
问题描述
在当前前后端分离的项目中,前端以接口的形式向后端请求数据,遇到后端服务使用长整型(Long)存储数据,为了避免数据重复,特意在这个长整型上增加了一位标识位,因此此长整型固定长度18位(十进制),正常情况下长整型在java里十进制的位数大概是19位左右,所以后端没问题。
当前端请求数据时,发现接口返回的数据不正确,在最后一位少1(当时的现象)。
问题原因
后端存储有符合Long型数值最大为pow(2,63),即9223372036854775807。
前端存储数值只有Number类型,JS 遵循 IEEE 754 规范,采用双精度存储(double precision),共占用 64 bit,为了更大的存储数据,使用:
1位标识符号位;
11位标识指数位,即多少次方;
52位标识尾数。
所以前端所能存储的最大的精确整数,是pow(2,53)-1,即9007199254740991,大概是16位的10进制数字。
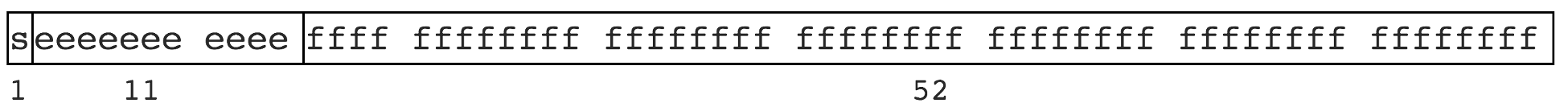
因此当后端传输的数值类型超过pow(2,53)-1时,前端就会损失精度,所以最后一位少1只是特例,甚至后面几位的精度不准确都是很正常的。
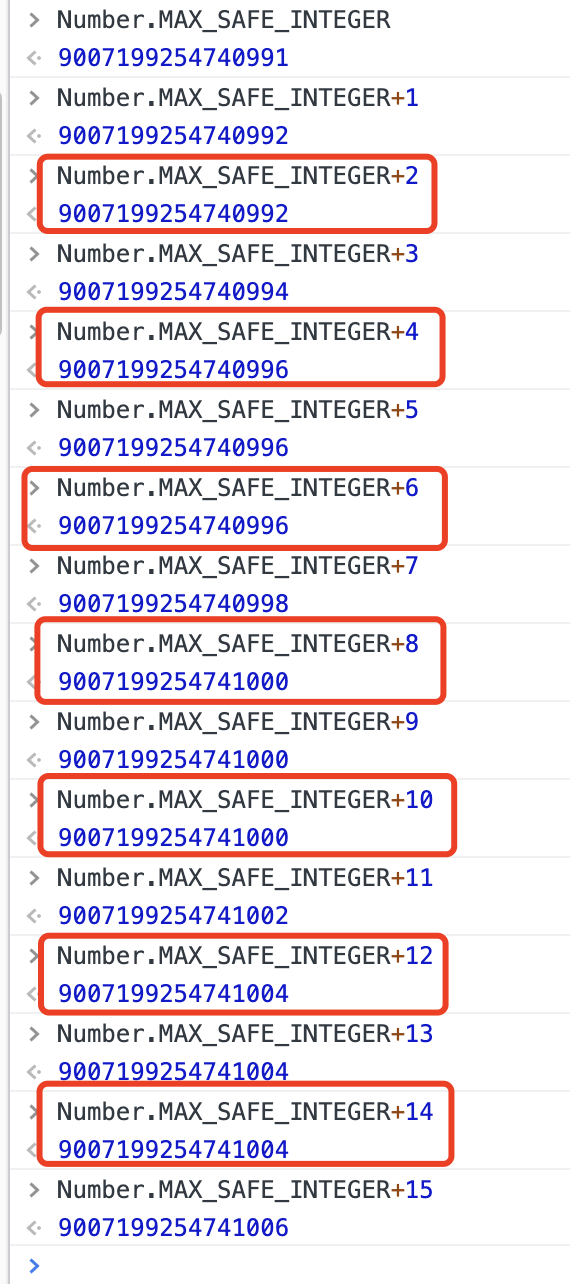
可以发现,每隔1,精度准一次,那么分析原因:

以此类推,每逢2的时候,数值都是正确的,因为此时失精位数是1位,依然不是精确数值,但失精那一位刚好是0,所以只是看起来是正确的数值而已,并不代表精确。
问题解决
解决办法一:
使用ToStringSerializer的注解,让系统序列化时,保留相关精度,需要将入参、出参均需修改。
@JsonSerialize(using=ToStringSerializer.class)
private Long id;解决办法二:
使用全局配置,将转换时实现自动ToStringSerializer序列化,简单有效,不过过于粗暴。
@Override
public void configureMessageConverters(List<HttpMessageConverter<?>> converters) {
MappingJackson2HttpMessageConverter jackson2HttpMessageConverter =
new MappingJackson2HttpMessageConverter();
ObjectMapper objectMapper = new ObjectMapper();
/**
* 序列换成json时,将所有的long变成string
* 因为js中得数字类型不能包含所有的java long值
*/
SimpleModule simpleModule = new SimpleModule();
simpleModule.addSerializer(Long.class, ToStringSerializer.instance);
simpleModule.addSerializer(Long.TYPE, ToStringSerializer.instance);
objectMapper.registerModule(simpleModule);
jackson2HttpMessageConverter.setObjectMapper(objectMapper);
converters.add(jackson2HttpMessageConverter);
}
解决办法三:
缩减Long整型的数值范围,减少到pow(2,53)-1的精度即可。目前我们采用的是此解决方案。
以上三种方案以实际需求为准,没有优劣之分。
参考文章:
https://blog.csdn.net/u010398771/article/details/103520893
https://blog.csdn.net/u010028869/article/details/86563382

