MySQL主从延时长,要怎么优化?
MySQL主从复制,读写分离是互联网常见的数据库架构,该架构最令人诟病的地方就是,在数据量较大并发量较大的场景下,主从延时会比较严重。
为什么主从延时这么大?
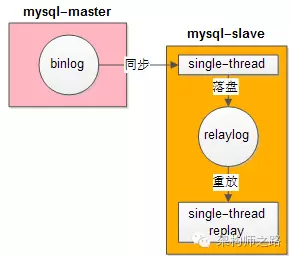
答:MySQL使用单线程重放RelayLog。
应该怎么优化,缩短重放时间?
答:多线程并行重放RelayLog可以缩短时间。
多线程并行重放RelayLog有什么问题?
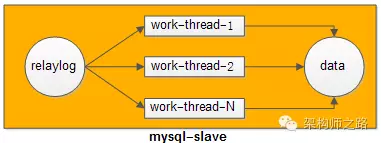
答:需要考虑如何分割RelayLog,才能够让多个数据库实例,多个线程并行重放RelayLog,不会出现不一致。
为什么会出现不一致?
答:如果RelayLog随机的分配给不同的重放线程,假设RelayLog中有这样三条串行的修改记录:
update account set money=100 where uid=58;
update account set money=150 where uid=58;
update account set money=200 where uid=58;
如果单线程串行重放:能保证所有从库与主库的执行序列一致。
画外音:最后money都将为200。
如果多线程随机分配重放:多重放线程并发执行这3个语句,谁最后执行是不确定的,最终从库数据可能与主库不同。
画外音:多个从库可能money为100,150,200不确定。
如何分配,多个从库多线程重放,也能得到一致的数据呢?
答:相同库上的写操作,用相同的线程来重放RelayLog;不同库上的写操作,可以并发用多个线程并发来重放RelayLog。
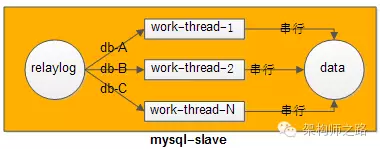
如何做到呢?
答:设计一个哈希算法,hash(db-name) % thread-num,库名hash之后再模上线程数,就能很轻易做到,同一个库上的写操作,被同一个重放线程串行执行。
画外音:不同库上的重放,是并行的,就起到了加速做用。
这个方案有什么不足?
答:很多公司对MySQL的使用是“单库多表”,如果是这样的话,仍然只有一个库,还是不能提高RelayLog的重放速度。
启示:将“单库多表”的DB架构模式升级为“多库多表”的DB架构模式。
画外音:数据量大并发量大的互联网业务场景,“多库”模式还具备着其他很多优势,例如:
(1)非常方便的实例扩展:DBA很容易将不同的库扩展到不同的实例上;
(2)按照业务进行库隔离:业务解耦,进行业务隔离,减少耦合与相互影响;
(3)非常方便微服务拆分:每个服务拥有自己的实例就方便了;
“单库多表”的场景,多线程并行重放RelayLog还能怎么优化?
答:即使只有一个库,事务在主库上也是并发执行的,既然在主库上可以并行执行,在从库上也应该能够并行执行呀?
新思路:将主库上同时并行执行的事务,分为一组,编一个号,这些事务在从库上的回放可以并行执行(事务在主库上的执行都进入到prepare阶段,说明事务之间没有冲突,否则就不可能提交),没错,MySQL正是这么做的。
解法:基于GTID的并行复制。
从MySQL5.7开始,将组提交的信息存放在GTID中,使用mysqlbinlog工具,可以看到组提交内部的信息:
20181014 23:52 server_id 58 XXX GTID last_committed=0 sequence_numer=1
20181014 23:52 server_id 58 XXX GTID last_committed=0 sequence_numer=2
20181014 23:52 server_id 58 XXX GTID last_committed=0 sequence_numer=3
20181014 23:52 server_id 58 XXX GTID last_committed=0 sequence_numer=4
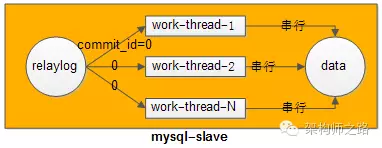
和原来的日志相比,多了last_committed和sequence_number。
什么是last_committed?
答:它是事务提交时,上次事务提交的编号,如果具备相同的last_committed,说明它们在一个组内,可以并发回放执行。
总结
MySQL并行复制,缩短主从同步时延的方法,体现着这样的一些架构思想:
- 多线程是一种常见的缩短执行时间的方法;
画外音:例如,很多crontab可以用多线程,切分数据,并行执行。
- 多线程并发分派任务时,必须保证幂等性:MySQL提供了“按照库幂等”,“按照commit_id幂等”两种方式,很值得借鉴;
画外音:例如,群消息,可以按照group_id幂等;用户消息,可以按照user_id幂等。
具体到MySQL主从同步延时:
- mysql5.5:不支持并行复制,大伙快升级MySQL版本;
- mysql5.6:按照库并行复制,建议使用“多库”架构;
- mysql5.7:按照GTID并行复制;
思路比结论重要,希望大家有收获。

